Evergreen Performance Bulletin 2021-06-14
As always, please let me know if you have any suggestions whatsoever.
Link to the last and next bulletins.
Updates
Host Drawdown Job Reduces Idle Time ~5x in Week-long rhel80-small Test
When this feature is turned on for a distro, a host drawdown job is created for that particular distro when that distro is very overallocated (host queue ratio < .25). The job has safeguards to make sure that it does not terminate so many hosts that the queue ratio will increase past 1 (which represents enough hosts to meet target time). We further require that hosts be idle for 30 seconds or more, which should give enough time for them to pick up new tasks if any exist (especially considering the fact that GetNextTask will run quickly on a near-empty queue). Drawdown jobs will be created until the host queue ratio rises above .25. This heuristic is almost certainly suboptimal, but .25 has worked well as a first estimate.
See #4633 for software implementation details.
As a test of this new functionality, I went to the rhel80-small distro page and set the Host Overallocation Rule to “terminate-hosts-when-overallocated” on Thursday, June 10th.
In order to get a rough initial estimate of the effect of the termination jobs, I compared two queue-exhaustion events, one before I turned on the feature and one after.
Looking at the first event, we started at just under 1000 hosts. Five minutes after the queue emptied (roughly), we had 375 idle machines. For this second event, we started out at just over 1000 hosts, and pre-emptively killed about 400 hosts, leaving us with about 35 idle hosts five minutes after the queue emptied.
I then let the distro run normally for about a week. The initial results were borne out by further data.
The reduction in idle time is plainly visible on this chart:
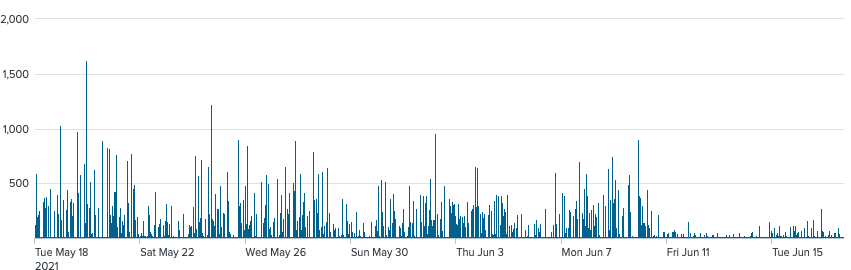
However, this overstates things somewhat, because more hosts were spun up as a result of greater termination propensity. The three Fridays prior to the change averaged to 8,487 startups. Friday the 11th had 9,263 host startups, for a +776 difference. Evergreen devs have told me that the average time to start up a host is 2 minutes, and a brief spot check confirmed this is roughly correct. This gives us 1,552 extra startup minutes.
The average summed idle time, over the last four Fridays, was 60 thousand minutes. UTC Friday 11th Jun has a summed idle time of 9,309 minutes, with an estimated 1,552 extra startup minutes, for a roughly 5.5x reduction.
With an instance type of m4.xlarge, spot instances are currently $0.0663 per minute in NVA. This new feature therefore provides, in the operation of rhel80-small, a savings of roughly
\[(\frac{\$0.0663} {\text{Hour in N. Virginia}}) * (\frac{1 \text{ hr}} {60\text{ minutes}}) * (\frac{60000-10861\text{ minutes}}{\text{day}}) \approx \frac{\$54}{day}\]more generally,
\[(\frac{\$\text{price}} {\text{Hour in N. Virginia}}) * (\frac{1 \text{ hr}} {60\text{ minutes}}) * (\frac{\text{idle minutes with no drawdown}}{\text{day}}) * \frac{4.5}{5.5} \approx \frac{\$X\text{ saved}}{day}\]This represents roughly $17k/yr savings for the operation of rhel80-small, based on an average idle time per day of 50,784 over the last 30 days.
We can estimate the amount we would save by rolling out to rhel80-medium with the same equation. Load is largely similar between the two distros. The current spot price of m4.2xlarge is 19.24 cents per hour, which gives $48.6k/yr by the above equation.
So, we could save around $65k/yr using this feature just on these two distros, assuming we use spot and never on-demand. This is only an initial estimate, but is conservative (likely an underestimate).
Consequently, Jonathan and I have turned on this feature for rhel80-medium. I propose we turn on this feature by default for all ephemeral, by-the-minute distros.
Minimal QoS/Task Wait Impact
Despite normal levels of task activity, the average number of overdue tasks was not noticeably higher after this feature was turned on. If anything, it appears lower, but this is probably just noise.
There is a similar trend in 99th percentile time_to_start_from_unblocked.
If there was any impact in performance, it was swamped out by existing noise, for both the time to 99th percentile task wait time:

as well as the average number of non-grouped overdue tasks in the distro queue:

Weekly Idle Data Confirm ~5x Reduction
The overall conclusion is very similar to that of the above savings calculations, if we look at the first full week with this feature turned on (week of Mon Jun 14th).
We see no or negligible additional starts in the weekly data, looking at the week of the 14th.

Comparing the week of the 14th to the average of the weeks of May 17th, 24th, and 31st, we get an average reduction from 50,392 idle minutes per day to 9,385. This gives a reduction coefficient of \(\frac{4.4}{5.4}\).

experimentation standards
In the future, power analyses may be useful, as mentioned in earlier bulletins. For example, a power analysis might be useful to determine if I looked at enough data to detect a difference in performance, if one existed. However, for the current analysis I want to move quickly. Properly modeling the data would be challenging. For example, we can see in the chart below that idle time as a proportion of total task runtime follows a different long-term distribution for week days and weekend days.
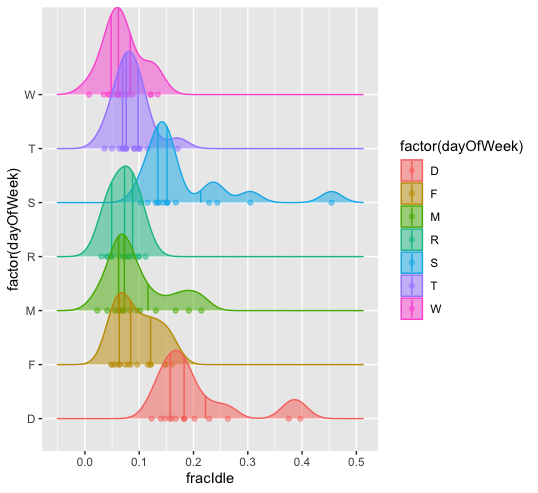
The effect of host drawdowns on idle time was dramatic enough that I’m confident this doesn’t represent a random aberration, and am similarly confident that performance impacts have been minimal.
New Epic: Structured, Granular Alerting with Prometheus Alert Manager
This will address many of the alerting difficulties outlined in prior newsletters. Scope is approved, and the epic is second up to execute.
fixing idle time metric
Future Directions
Understanding Idle Time Tradeoffs
This is the most important new area of inquiry, IMO. That is to say, it has the greatest expected value for return on information.
There are three main reasons we need to better understand the tradeoffs associated with host idleness:
- Savings: The host drawdown approach above should take care of roughly 4/5ths of the idle host time we currently see. As such, we can consider the low-hanging fruit picked and move on to other topics for now.
- Windows Performance: We currently regulate windows host costs by setting low distro-level max hosts limits. This results in very bad performance. It might be possible to get equivalent cost savings without as heavy as a toll on performance. Hourly distros are not impacted by the host drawdown project and should be our first priority going forward.
- Making sure performance increases aren’t too costly: In general, I think it is a good idea to have some kind of feedback rule that increases host allocation as a response to poor performance (e.g. time since queue was last cleared, number of long-wait tasks). Before the host-drawdown job, this might have resulted in greater idle time, but now I think this isn’t nearly as much of a concern.
Task Packing to decrease idle host time for Windows
There has been no new analysis since the last bulletin. Once the host drawdown project is rolled out to all ephemeral by-the-minute distros, this will be my biggest focus for performance quick wins.
Future Directions Not Considered
~~~
Blotter
(For one-off or temporary performance issues)
Daily Task Level Not Related to Variables of Interest
From eyeballing rhel80-small charts, I think total daily task level is not very related to idle host count, host start count, tasks overdue or perc99 task wait. I think some function of a momentary variable, like # of tasks added per period, would be more insightful. There is likely some relationship to burstiness, total number of new tasks per hour/minute, and total system load that would have a closer relationship with these variables of interest.