Evergreen Performance Bulletin 2021-03-22
As always, please let me know if you have any suggestions whatsoever.
Link to the last and next bulletins.
Updates
New Epic: Structured, Concern-aware Alerting
This will address many of the alerting difficulties outlined in last sprint’s newsletter. In Team Review
Replacement for Makespan Metric is Fixed
This is currently in the main Evergreen Dashboard, under the title “number of time chunks of length MaxDurationThreshold needed to clear queue with current hosts”, because it’s not really clear what “host queue ratio” means. The Y axis is logarithmic in order to allow visualization of the detail of day-to-day operations, which should top out at 1 if sufficient hosts have been provisioned, simultaneously with the moonshots that occur when max_total_dynamic_hosts has been reached.
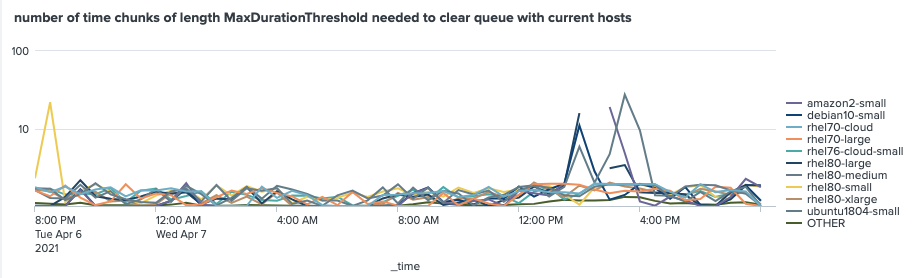
“host queue ratio” is currently very useful. However the default MaxDurationThreshold, which is equivalent to the target time for the host allocator, is 30 minutes. Our long-term goal for task wait SLAs is something more like 5 minutes. If we use a lower MaxDurationThreshold to enable this, “host queue ratio” will become less informative, as it does not take into account long tasks. This presents a long-term threat to the paradigm, but only under certain conditions which it will most likely be possible to avoid.
Future Directions
Understanding Idle Time Tradeoffs
This is the most important new area of inquiry, IMO. That is to say, it has the greatest expected value for return on information.
There are three main reasons we need to better understand the tradeoffs associated with host idleness:
- Savings: We could potentially save hundreds of thousands of dollars a year by understanding how to minimize the total time host spend idle or spinning up. It may also be the case that there are better or worse configurations for performance with similar costs.
- Windows Performance: We currently regulate windows host costs by setting low distro-level max hosts limits. This results in very bad performance. It might be possible to get equivalent cost savings without as heavy as a toll on performance.
- Making sure performance increases aren’t too costly: In general, I think it is a good idea to have some kind of feedback rule that increases host allocation as a response to poor performance (e.g. time since queue was last cleared, number of long-wait tasks). However, this will likely result in greater idle time. Before we take any action that significantly increases the host idle time, we should understand the tradeoffs.
I’ve begun to look into this. Some important facts and preliminary work:
fixing idle time metric
This is a prerequisite for other work. https://jira.mongodb.org/browse/EVG-14363
experimentation standards
The current plan to evaluate the effect of idle host changes is to turn on new features on alternate Wednesdays. In other words, I will be using a within-subject design. This will avoid distro matching problems that would be caused by a split treatment by distro (i.e, between-subject design). First, I need to get an idea of what idle host time metric to use, and what its variability is EVG-14410. This will allow me to conduct power analysis to make sure that we will be able to identify an effect if one exists.
startup considerations for dynamic distros
We can describe the wasted-time tradeoffs as such:
\[\mathbf{E}(\text{unused host time})=\mathbf{E}(\text{idle time}) \\ + \mathbf{E}(\text{startup time})\]That is, given that a task may need to be picked up by a host at some unknown time, there is some chance we will idle while waiting for a task, but if we terminate the host and then need it later, we will have to waste startup time. We can split this up according to whether or not the host is idle-terminated, and then make substitutions:
\[\mathbf{E}(\text{unused host time})=\mathbf{P}(\text{idle termination})[\mathbf{E}(\text{idle time|idle termination}) + \mathbf{E}(\text{startup time|idle termination})] \\ + \mathbf{P}(\text{no idle termination}) * \mathbf{E}(\text{idle time|no idle termination})\]We don’t need to include \(\mathbf{E}(\text{startup time|no idle termination})\), which is zero. Additionally, \(\mathbf{E}(\text{idle time|idle termination})=\text{idleTimeCutoff}\). We can further simplify:
\[\mathbf{E}(\text{unused host time})=\mathbf{P}(\text{idle termination})[\text{idleTimeCutoff} + \mathbf{E}(\text{startup time|idle termination})] \\ + \mathbf{P}(\text{no idle termination}) * \mathbf{E}(\text{idle time|no idle termination})\]We currently set idleTimeCutoff to 4 minutes and Brian told me \(E(\text{startup time}|\text{idle termination})\), the average startup time, is 2 for typical dynamic linux distros.
As such, we might be able to get significant idle-time savings simply by cutting the idle time threshold from 4 minutes to 2.
However, this depends on the performance of FindNextTask(.
If we make the cutoff too small, we will terminate hosts during times of high need due to the delay introduced to FindNextTask( by high load.
Take \(T\) as the random variable of times it takes a host to get the next task, either due to waiting for computation to finish or because no task is available:
\[\mathbf{E}(\text{unused host time})=\mathbf{P}(\text{idleTimeCutoff} < T)[\text{idleTimeCutoff} + \mathbf{E}(\text{startup time|idle termination})] \\ + \mathbf{P}(T < \text{idleTimeCutoff}) * \mathbf{E}(\text{idle time|no idle termination})\]The above equation is likely vulnerable to further analysis, but I have run out of time for this week.
Moving on, I think that the distribution of times \(T\) is not stationary in time, and is usually very high-valued or very low-valued. This would make it hard to use many traditional time series analyses. However, we can exploit this to reduce our cost. When the queue is completely empty, and we have many hosts, we can expect to wait a long time for a new task. When the queue is full, the average wait time will be small. In other words, the host queue ratio allows us to approximate \(\mathbf{P}(\text{idle termination})\) without worrying about optimizing a fixed cutoff time criterion.
This effort will be tracked by EVG-14350.
Task Packing to decrease idle host time for Windows
I’ve been looking at windows-64-vs2017-large more closely, on account of its poor performance. There are idle hosts up to 2 hours after the queue is exhausted. Currently, hosts request tasks as soon as they are free, which guarantees that the task at the head of the queue is taken off the queue in the fastest time possible. However, in the case of windows distros, the performance is degraded to the point of multiple-hour waits, due to the distro max hosts limit. We should modify our strategy, because it makes no sense to mind seconds and let hours go by.
We are currently able to predict when a queue is in terminal decline, using the new host queue ratio metric. As such, if we were able to use some coordination step that added about a minute to each task’s wait, without worrying about modes, it would still be worth it if we were able to decrease idle time enough to justify the lifting of distro max host limits. However, this could involve significant reworking of the task scheduling framework.
Another possibility would be to mark hosts nearing the end of their allotted hour as unable to accept new tasks, if the host queue ratio is low enough.
A third possibility is to have hosts include the amount of time they have left in their current hour when requesting tasks, and only accept tasks that are less than that amount of time.
This needs to be thought out more before it is implemented.
Future Directions Not Considered
~~~
Blotter
(For one-off or temporary performance issues)